Erweiterte Daten (Advanced Data)¶
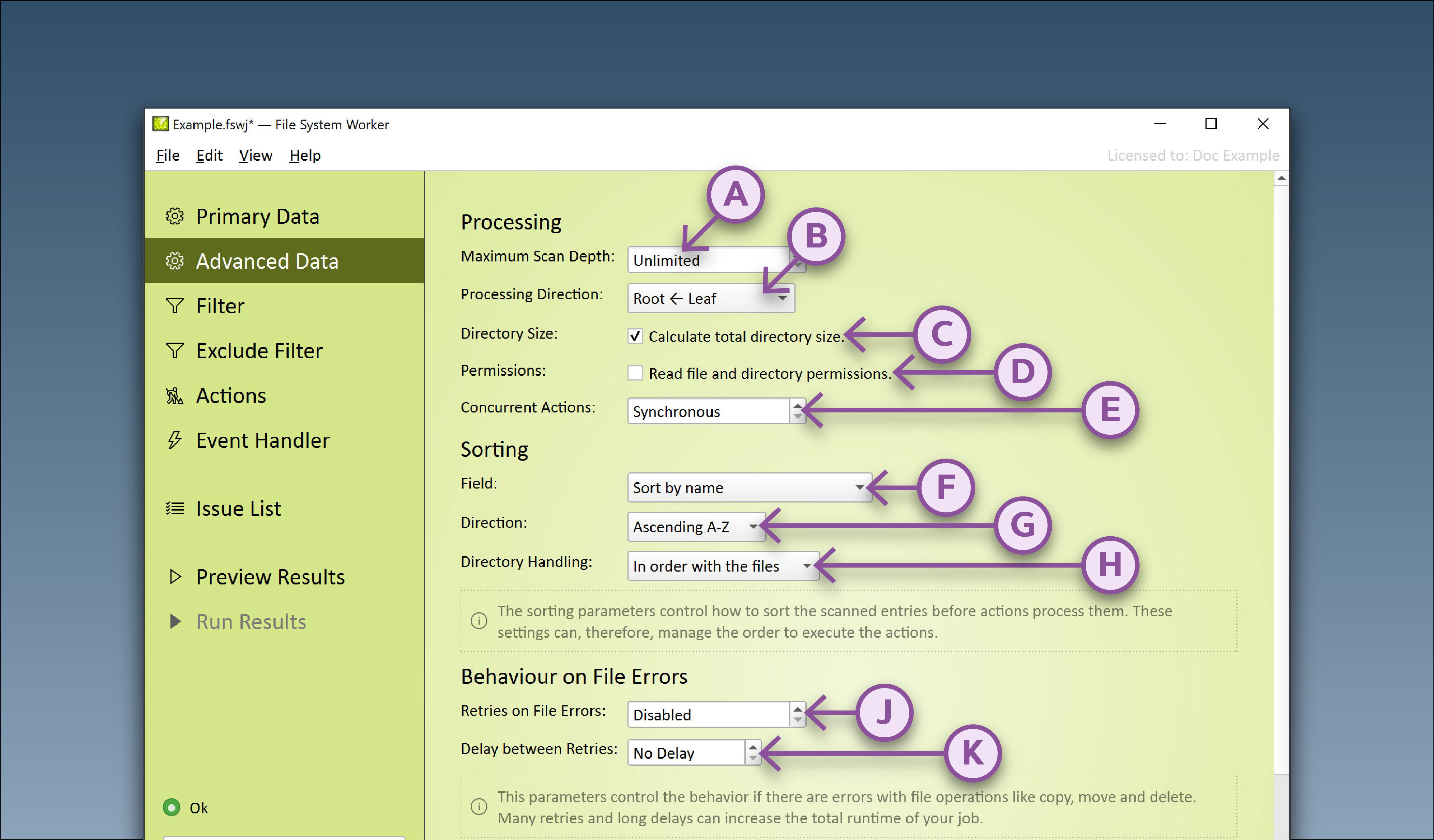
A Mit der Einstellung Maximum Scan Depth limitierst du die Scan-Tiefe. Siehe dazu Maximum Scan Depth.
B Die Einstellung Processing Direction kontrolliert die Richtung in welcher Aktionen beim Scannen ausgeführt werden. Siehe dazu Processing Direction.
C Bei Directory Size kannst du die Berechnung der Verzeichnisgrösse einschalten. Ist die Einstellung aktiviert, entspricht das Size Attribut bei Verzeichnissen der Summe aller darin enthaltenen Elemente. Siehe dazu Directory Size.
D Mit der Einstellung bei Permissions, kannst du die Abfrage detaillierter Berechtigungen für jedes Element im Dateisystem aktivieren. Diese Abfrage verlangsamt den Scanvorgang jedoch, da viel mehr Attribute abgefragt werden müssen. Siehe dazu Permissions.
E Die Einstellung Sorting/Field bestimmt nach welchem Attribut sortiert werden soll. Siehe dazu Sorting.
F Mit der Einstellung Sorting/Direction legst du die Sortierrichtung fest. Siehe dazu Sorting.
G Sorting/Directory Handling bestimmt wie Verzeichnisse sortiert werden. Siehe dazu Sorting.
J Falls bei bei einer Dateioperation Fehler auftreten, kannst du mit der Einstellung Retries on File Errors mehrere Versuche aktivieren. Siehe dazu Behaviour on File Errors.
K Mit der Einstellung Delay between retries konfigurierst du die Verzögerung zwischen zwei Versuchen einer Dateioperation. Siehe dazu Behaviour on File Errors.

L Aktivierst du Preview/Filter werden nur die passenden Einträge für die Vorschau im Speicher gehalten. Dies kann bei sehr grossen Jobs den Speicherverbrauch erheblich reduzieren. Siehe dazu Preview.
M Mit Preview/Limit stoppst du die Vorschau nach einer bestimmten Anzahl von Elementen. Dies ist Sinnvoll, wenn du dir nur einen kleinen Überblick eines sehr grossen Dateisystems verschaffen möchtest. Natürlich sind dadurch Grössenberechnungen von Verzeichnissen falsch, da nur ein Teil der Elemente gescannt wird. Siehe dazu Preview.
N Mit Calculate Hash aktivierst du die Prüfsummenberechnung für jede passende Datei. Für diese Berechnung muss jede Datei komplett gelesen werden, was deutlich mehr Ressourcen benötigt und den Scanvorgang verlangsamt. Siehe dazu Hash Calculation.
P Aktivierst du diese Option, wird die Prüfsumme nur für auf den Filter passende Dateien berechnet. Siehe dazu Hash Calculation.
Maximum Scan Depth¶
Mit dieser Einstellung kontrollierst du die Scan-Tiefe, also wieviele Unterverzeichnisse in den Scan einbezogen werden.
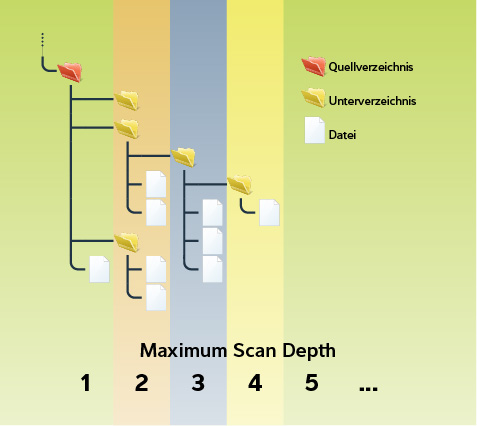
Ist die Einstellung auf Unlimited gesetzt (entspricht dem Wert 0 ), dann gibt es keine Einschränkung. Es werden alle Unterverzeichnisse eines Quellverzeichnisses gescannt.
Bei dem Wert
1wird nur das Quellverzeichnis selbst und der darin enthaltenen Dateien einbezogen.Bei dem Wert
2wird das Quellverzeichnis und dessen Unterverzeichnisse gescannt und mit jedem höheren Wert eine zusätzliche Unterverzeichnisebene.
Processing Direction¶
Diese Einstellung kontrolliert die Richtung in welcher Aktionen beim Scannen ausgeführt werden. Dabei gibt es zwei Möglichkeiten:
Root ← Leaf
Root → Leaf
Die folgende Illustration zeigt ein Dateisystem welches als Illustration für die folgenden beiden Beispiele
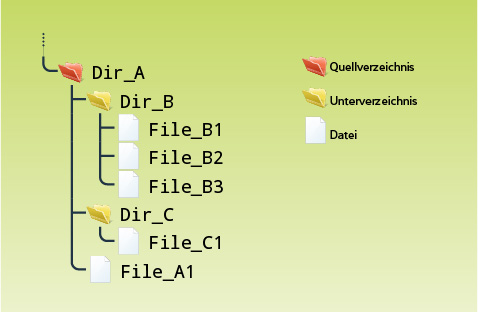
Mit der Einstellung Root → Leaf werden die Aktionen direkt nach dem Scan eines Verzeichnisses ausgeführt, noch bevor der Scan in den Unterverzeichnissen fortgesetzt wird. Im oben gezeigten Dateisystem werden die Aktionen wie folgt ausgeführt:
Scan von Dir_A
Aktionen für Dir_B ausführen.
Aktionen für Dir_C ausführen.
Aktionen für File_A1 ausführen.
Scan von Dir_B
Aktionen für File_B1 ausführen
Aktionen für File_B2 ausführen
Aktionen für File_B3 ausführen
Scan von Dir_C
Aktionen für File_C1 ausführen
Bei der Einstellung Root ← Leaf werden die Aktionen erst ausgeführt, nachdem alle Unterverzeichnisse gescannt wurden. Für das oben gezeigte Dateisystem werden die Aktionen folgendermassen ausgeführt:
Scan von Dir_A
Scan von Dir_B
Aktionen für File_B1 ausführen
Aktionen für File_B2 ausführen
Aktionen für File_B3 ausführen
Scan von Dir_C
Aktionen für File_C1 ausführen
Aktionen für Dir_B ausführen.
Aktionen für Dir_C ausführen.
Aktionen für File_A1 ausführen.
In welcher Reihenfolge die Unterverzeichnisse gescannt und die Aktionen ausgeführt werden, bestimmt die Sortierung. Siehe dazu Sorting.
Die Richtung in welche die Aktionen ausgeführt werden ist immer dann wichtig, wenn du mit einer Aktion Dateien löscht, umbenennst oder verschiebst. In diesem Fall ist möglicherweise ein Unterverzeichnis bereits verschwunden, bevor es gescannt werden kann. Lass dann die Einstellung auf dem Standardwert Root ← Leaf.
Falls du eine Liste bestimmter Dateien oder Verzeichnissen erstellst, möchtest du vielleicht zuerst die Einträge aus den untersten Verzeichnissen sehen. Hier bietet sich die Einstellung Root → Leaf an.
Directory Size¶
Aktivierst du die Option Directory Size werden in einem Verzeichnis die Summe aller Dateigrössen gespeichert. Ist die Option nicht aktiviert, entspricht die Grösse eines Verzeichnisses dem beim Betriebssystem abgefragten Wert.
Einige Dinge solltest du dabei beachten:
Werden Dateien und Verzeichnisse mit einem Ausschlussfilter ignoriert (siehe Ausschluss Filter (Exclude Filter)), dann werden ausgeschlossenen Dateien nicht zu der Summe hinzugefügt.
Wenn du nur die passenden Dateien für die Vorschau behältst (Option Preview/Limit), sind die angezeigten Grössen in der Vorschau nicht korrekt.
Die Grösse eines Verzeichnisses wird am Ende eines kompletten Scans berechnet. Falls deine Aktionen oder Filter diese Summe verwenden, musst du die Ausführrichtung Root ← Leaf verwenden. Siehe dazu Processing Direction. In der anderen Richtung stimmen die grössen noch nicht, da ja noch nicht alle Unterverzeichnisse gescannt wurden.
Permissions¶
Aktivierst du die Option bei Permissions werden zusätzliche Attribute beim Scan des Dateisystems abgefragt. Diese Attribute werden als Text in dem Feld Permissions gespeichert. Das Format und die abgefragten Attribute sind je nach Betriebssystem unterschiedlich.
Für Windows sieht das Permissions Feld folgendermassen aus:
attributes=hidden owner="NT SERVICE\TrustedInstaller" group="NT SERVICE\TrustedInstaller"
Das Feld enthält einzelne Schlüssel und Wert Paare im Format [Schlüssel]=[Wert]. Die einzelnen Paare sind durch Leerzeichen voneinander getrennt.
Folgende Schlüssel existieren:
Schlüssel |
Beschreibung |
|---|---|
|
Attribute eines Elements mit Komma getrennt. |
|
Der Besizter eines Elements. |
|
Die Gruppe eines Elements. |
attributes¶
Dieser Schlüssel enthält mögliche Attribute eines Elements des Dateisytstems. Die einzelnen Attribute werden dabei mit einem Komma, ohne Leerzeichen getrennt. Ist kein Attribut gesetzt, dann existiert der Schlüssel ohne Wert.
Die folgende Tabelle zeigt alle möglichen Attribute auf.
Attribut |
Beschreibung |
|---|---|
|
Dieses Attribut kann von Windows Software, beispielsweise für Backups verwendet werden. |
|
Komprimierte Dateien oder Verzeichnisse. |
|
Verschlüsselte Dateien oder Verzeichnisse. |
|
Versteckte Elemente. |
|
Offline-Elemente sind nicht sofort verfügbar und liegen auf einem Offline-Speicher. |
|
Elemente welche nicht beschrieben werden können. |
|
Sparse-Dateien. |
|
System-Dateien. |
|
Temporäre Elemente. |
owner und group¶
Diese beiden Schlüssel geben den Besitzer und die Gruppe für ein Element an. Falls der damit Verbundene Account-Name ermittelt werden kann, wird dieser in Anführungszeichen hinter dem Schlüssel angegeben.
owner="NT SERVICE\TrustedInstaller" group="NT SERVICE\TrustedInstaller"
Kann der Account-Name nicht ermittelt werden, wird der Security Identifier des Accounts, ohne Anführungszeichen angegeben:
owner=S-1-5-21-1004336348-1177238915-682003330-512 group=S-1-5-32-544
Sorting¶
Mit den Einstellungen im Abschnitt Sorting definierst du die Sortierung der Elemente während eines Scans. Diese Sortierung ist sowohl in der Vorschau sichtbar, hat aber auch einen direkten Einfluss auf die Reihenfolge des Scans und der Ausführung von Aktionen.
Für jedes Verzeichnis passiert folgendes:
Alle Elemente eines Verzeichnisses werden abgefragt.
Die abgefragten Elemente werden sortiert.
Unterverzeichnisse werden gescannt, Filter angewendet und Aktionen ausgeführt.
Field¶
Diese Einstellung konfiguriert welches Attribut für die Sortierung verwendet werden soll. Dabei existieren folgende Optionen:
No Sorting |
Die Elemente werde ohne Sortierung übernommen. |
Sort by name |
Die Elemente werden nach dem Namen sortiert. Dabei wird die Gross-/Kleinschreibung ignoriert. |
Sort by size |
Die Elemente werden nach der Grösse sortiert. |
Sort by crated date/time |
Die Elemente werden nach der Zeit und dem Datum der Erstellung sortiert. |
Sort by last modified date/time |
Die Elemente werden nach der Zeit und dem Datum der letzten Modifikation sortiert. |
Sort by last accessed date/time |
Die Elemente werden nach der Zeit und dem Datum des letzten Zugriffs sortiert. |
Direction¶
Die Einstellung Direction konfiguriert die Richtung der Sortierung.
Ascending A-Z |
Absteigende sortierung. |
Descending Z-A |
Aufsteigende sortierung. |
Directory Handling¶
Mit dieser Einstellung kannst du Verzeichnisse gesondert sortieren.
In order with the files |
Es wird nicht zwischen Dateien und Verzeichnissen unterschieden. |
Order them before files |
Verzeichnisse kommen immer vor allen Dateien. |
Order them after files |
Verzeichnisse kommen immer nach allen Dateien. |
Behaviour on File Errors¶
Mit den Einstellungen bei Behaviour on File Errors kontrollierst du, wie oft eine Operation bei einem Fehler wiederholt werden soll. Führst du ein Job auf einem Netzwerklaufwerk aus, welches aktiv von anderen Prozessen genutzt wird, können einzelne Operationen scheitern da bestimmte Dateien und Verzeichnisse blockiert sind. Diese Probleme löst du oft, indem diese Operationen mit einer bestimmten Verzögerung mehrfach wiederholt werden.
Der Wert Retries on File Errors konfiguriert die Anzahl der Wiederholungen und aktiviert damit dieses Feature.
Mit Delay between Retries definierst du, wie lange zwischen Wiederholungen gewartet werden soll. Der Wert steht dabei für Sekunden.
Preview¶
Die Einstellungen unter Preview betreffen nur die Vorschau und haben damit keinen Einfluss auf die normale Jobausführung.
Mit Filter limitierst du die Vorschau auf Elemente welche auf deinen Filter passen. Für einen Job welches ein riesiges Dateisystem scant, reduziert dies den Speicherverbrauch erheblich. Beachte jedoch die folgenden Nachteile:
Berechnete Verzeichnisgrössen stimmen möglicherweise nicht mehr.
Beim Testen findest du so keine Elemente, welche möglicherweise noch Teil des Filters werden sollten.
Die zweite Option Limit, limitiert den Scan auf eine bestimmte Anzahl von Elementen. Ist diese Zahl erreicht, wird der Scan abgebrochen. Auch diese Option ist praktisch um eine Vorschau eines sehr grossen Dateisystems zu bekommen. Dabei hast du die selben Nachteile wie bei der ersten Option.
Hash Calculation¶
Mit den Optionen unter Hash Calculation kannst du eine Prüfsumme für jede Datei berechnen, welche auf deinen Filter passt. Dabei wird die Datei komplett gelesen, was deutlich mehr Ressourcen braucht und den Scanvorgang langsamer macht.
Bei Calculate Hash wählst du den gewünschten Prüfsummenalgorithmus. Zur Auswahl stehen:
MD5- nicht EmpfohlenSHA1- nicht EmpfohlenSHA3-256SHA3-384SHA3-512- unsere Empfehlung
Aktivierst du die zweite Option, wird eine Prüfsummen für jede Datei berechnet — unabhängig davon ob diese auf den Filter passt oder nicht.
Die Prüfsumme jeder Datei wird in dem Feld hash gespeichert. Sie kann für sehr viele verschiedene Zwecke verwendet werden:
Suche nach Duplikaten.
Aufdecken von Dateimanipulationen.
Verifizieren eines Kopiervorgangs.
…