User Directory Erweiterung¶
Einleitung¶
Die User Directory Erweiterung generiert Einträge für die Benutzerverzeichnisse und berechnet deren aktuelle Grösse.
Fakten¶
Name |
User Directory |
Bezeichner |
|
Version |
1.2 |
Funktionen |
Adapter |
Abschnitte |
|
Informationsblöcke |
|
Features¶
Erstellt Einträge für alle Benutzerverzeichnisse basierend auf bestehenden Werten eines Benutzerobjekts.
Jedes Verzeichnis kann getestet werden, ob es existiert.
Berechnet die Grösse und Limiten aller Benutzerverzeichnisse.
Bestehende Verzeichnisse und deren Limiten können mit eigenen Skripten generiert und bearbeitet werden.
Als Sicherheitsfeature verwendet die Erweiterung den externen Directory Scanner Service um die Grössen der Verzeichnisse zu berechnen, dadurch braucht nur dieser Service mit seiner limitierten Funktionalität erhöhte Privilegien.
Die berechnete Tabelle kann an verschiedene Anforderungen angepasst werden.
Übersicht und Architektur¶
Die User Directory Erweiterung bietet korrekte Verknüpfungen zu den Benutzerverzeichnissen. Zudem wird die Grösse und Limite von jedem dieser Verzeichnisse berechnet.
Für die Verwaltung von Benutzerprofilen existieren spezialisierte Systeme welche an die jeweiligen Firmenumgebungen angepasst sind. Diese Erweiterung unterstützt daher verschiedenste Methoden um die benötigten Verzeichnisse und Limiten aus bestehenden Werten zu extrahieren. Weiter kann jedes Verzeichnis getestet werden, ob es existiert, und so nur die tatsächlich vorhandenen Verzeichnisse angezeigt werden.
Mit dieser Flexibilität lässt sich die Erweiterung an jede Firmenumgebung anpassen.
Architektur¶
Die Architektur des Systems wird in the folgenden Illustration gezeigt:

Die Erweiterung läuft dabei im Kontext des Raptor Systems und greift für alle Dateiabfragen über ein eigenes API auf den Directory Scanner Service zu. Die Schnittstelle zwischen der Erweiterung und dem Directory Scanner Service ist mit SSL verschlüsselt und wird durch das Secret System geschützt.
Nur der Directory Scanner Service benötigt höhere Zugriffsrechte um auf die Profilverzeichnisse zuzugreifen. Durch die limitierte Funktionalität des Services lassen sich die höheren Zugriffsrechte nicht missbrauchen.
Funktionsweise¶
Die Erweiterung verwendet ein einfaches Auftragssystem, in dem jeder Auftrag eine Reihe von Zuständen (Schritten) durchläuft. Damit werden die Daten für das Raptor System erzeugt, sobald diese angefragt werden. Dieses System wurde gewählt, da es in jeder Situation stabil und zuverlässig läuft.
Starten eines neuen Auftrags¶
Fragt der Benutzer die Daten eines Objekts an, stellt der Server eine Anfrage nach den fehlenden Daten. Diese Anfrage erstellt automatisch einen neuen Auftrag innerhalb der Erweiterung. Der Prozess eines solchen Auftrags wird in der folgenden Illustration gezeigt.

In dem Prozessdiagramm erkennt man auch sehr klar den Vorteil des gewählten Systems. Ein Auftrag kann an einem beliebigen Punkt scheitern oder es kann eine Zeitüberschreitung auftreten, es wird dabei aber lediglich der einzelne Auftrag mit einem Fehler beendet. Probleme des Raptor Systems oder des Directory Scanner Service haben keinen Einfluss auf die Stabilität der Erweiterung.
Warten auf Eingabewerte¶
Im ersten Schritt des Auftrags wartet dieser, bis alle gewünschten Eingabewerte des Raptor Systems verfügbar sind. Falls die Konfiguration für Pfade oder Limiten Werte des Objekts benötigt, müssen diese zuerst verfügbar sein, bevor weitere Prozesse starten können.
An diesem Punkt überprüft der Auftrag, ob alle benötigten Werte verfügbar sind. Ist dies der Fall, wird dieser Schritt ohne verzögerung abgeschlossen. Falls benötigte Werte nicht geliefert werden, wird der Auftrag mit einem Fehler abgebrochen.
Falls gar keine Eingabewerte aus dem Objekt benötigt werden wird dieser Schnitt sogar ganz übersprungen.
Erzeugen der Pfade¶
Im nächsten Schritt werden die Pfade erzeugt, welche du in der Liste Paths konfiguriert hast (siehe Die Liste Paths). Alle Verzeichnispfade welche durch die Konfiguration erzeugt wurden, werden in einer Liste gesammelt.
Falls in diesem Schritt ein Problem auftritt wird der Auftrag mit einem Fehler abgebrochen. Dies kann beispielsweise durch einen Problem in einem Skript oder fehlerhaften Eingabewert passieren.
Nachdem alle Verzeichnispfade erfolgreich erzeugt wurden, wechselt der Auftrag zum nächsten Schritt.
Prüfen ob die Pfade existieren¶
Als nächstes werden die gesammelten Verzeichnisse überprüft, ob diese auch tatsächlich auf den jeweiligen Dateiservern existieren. Dazu wird eine Verbindung zum Directory Scanner Service hergestellt.
Der Auftrag wartet bei diesem Schritt bis die Resultate des Directory Scanner Service verfügbar sind. Verzeichnisse, welche nicht existieren, werden aus der Liste entfernt.
Falls keine Verzeichnispfade überprüft werden müssen, wird dieser Schritt übersprungen.
Der Auftrage wird in den folgenden Fällen mit einem Fehler abgebrochen: Bei einem Fehler von dem Directory Scanner Service, einer Zeitüberschreitung, falls die Abfrage eines Pfades abgelehnt wird oder falls keine Verbindung aufgebaut werden kann.
Erzeugen der Limiten¶
Die verbleibenden Verzeichnispfade werden mit den Einträgen abgeglichen, welche du in der der Liste Limits konfiguriert hast (siehe Die Liste Limits). Die berechnete Limite wird dem jeweiligen Verzeichnispfad hinzugefügt.
Falls keine Limiten konfiguriert sind, wird dieser Schritt übersprungen und alle Verzeichnispfade bleiben ohne Limit.
Bei fehlenden Eingabewerten oder einem Fehler in einem Konfigurierten Skript wird der Auftrag mit einem Fehler abgebrochen.
Berechnen der Verzeichnisgrössen¶
In dem nächsten Schritt werden die aktuellen Verzeichnisgrössen berechnet. Dazu wird eine Verbindung zum Directory Scanner Service aufgebaut und die Verzeichnispfade für die Berechnung übermittelt.
Der Auftrag wartet bei diesem Schritt bis die Resultate für alle Verzeichnispfade berechnet wurden. Die Dauer für die Resultate kann abhängig von der Grösse und Komplexität der Verzeichnisse sowie der Netzwerk- und Dateiserverperformance zwischen Sekunden bis Minuten dauern.
Es existieren daher für diesen Schritt zwei verschiedene Werte für eine Zeitüberschreitung. Ein Wert für alle Berechnungen bis zu diesem Punkt und ein zweiter Wert inklusive der Dauer für die Berechnung der Verzeichnisgrösse.
Die berechneten Resultate werden mit den Verzeichnispfaden gespeichert und der letzte Schritt gestartet.
Falls bei der Berechnung einen Fehler passiert oder eine Zeitüberschreitung eintritt wird der Auftrag mit einem Fehler abgebrochen.
Erstellen der Tabelle mit den Resultaten¶
Im letzten Schritt wird die Tabelle mit allen Resultaten erstellt und zurück an das Raptor System gesendet.
Fehler im Auftrag¶
Tritt in einem Auftrag ein Fehler auf, wird je nach schwere des Fehlers der ganze Auftrag abgebrochen, oder nur einzelne Verzeichnispfade nicht berechnet.
Konfiguration¶
Das Konfigurationsschema¶
Module
UserDirectory
Maximum length:
32Must match this regular expression:
[^\p{Zl}\p{Zp}\p{C}]+
Default Value:
User Directories
Maximum length:
64Must match this regular expression:
[a-zA-Z]+
Default Value:
primary
Complex list definition
Must be one of this:
Identifier,Name,Path,Limit,Size,Usage,Actions
Must not be empty.
Maximum length:
64Must match this regular expression:
[^\p{Zl}\p{Zp}\p{C}]+
Default Value:
Yes
Default Value:
No
Must not be empty.
Maximum length:
64Must match this regular expression:
[a-z0-9]+
Complex list definition
Must not be empty.
Maximum length:
64
Maximum length:
64Must match this regular expression:
[^\p{Zl}\p{Zp}\p{C}]+
Default Value:
[error]
List
Complex list definition
Maximum length:
64Must match this regular expression:
[-_a-zA-Z0-9]+
Maximum length:
128Must match this regular expression:
[^\p{Zl}\p{Zp}\p{C}]+
Default Value:
None
Maximum length:
64Must match this regular expression:
[-_a-zA-Z0-9]+
Maximum length:
64Must match this regular expression:
[-_a-zA-Z0-9]+
Default Value:
No
List
Complex list definition
Maximum length:
64Must match this regular expression:
[-_a-zA-Z0-9]+
Must be a valid regular expression.
Maximum length:
64Must match this regular expression:
[-_a-zA-Z0-9]+
Maximum length:
64Must match this regular expression:
[-_a-zA-Z0-9]+
Group
Default Value:
127.0.0.1
Must not be empty.
Must not be empty.
Must not be empty.
Der Wert ValueLabel¶
Mit dem optionalen Wert ValueLabel kannst du einen eigenes Label für den Wert mit den Benutzerverzeichnissen setzen. Du solltest diesen Text so kurz wie möglich halten, sowie auf Spezialzeichen verzichten. Überprüfe dein eigenes Label zusammen mit den anderen Werten im Client.

Das folgenden Beispiel konfiguriert das Label „Profiles“ für die Benutzerverzeichnisse:
<Value name="ValueLabel">Profiles</Value>
Wir empfehlen diesen Wert wegzulassen und dadurch den Standartwert zu verwenden.
Der Wert ValueSection¶
Mit dem optionalen Wert ValueSection verschiebst du die Tabelle mit den Benutzerverzeichnissen in einen anderen Abschnitt. Du konfigurierst hier den Bezeichner des Abschnitts. Aus diesem Bezeichner wird dann automatisch der Titel gebildet. Der Bezeichner darf maximal 64 Zeichen enthalten und nur Buchstaben enthalten.
Felder welche den selben Abschnittsbezeichner haben, werden automatisch unter diesem Abschnitt zusammengefasst. Es spielt dabei keine Rolle, ob der Abschnitt von dieser, oder einer anderen Erweiterung erstellt wurde. Einige zusätzliche Informationen zu den Abschnitten findest du im Kapitel Der Wert SectionOrder.

Der Titel eines Abschnitts wie er im Client dargestellt wird.¶
Das folgende Beispiel verschiebt die Tabelle mit den Benutzerverzeichnissen in den neuen Abschnitt „User Profile“:
<Value name="ValueSection">userProfile</Value>
Lässt diesen Wert weg, wird der Standartwert primary verwendet.
Der Wert ValueOrderIndex¶
Mit dem optionalen Wert ValueOrderIndex setzt du einen individuelle Position wo das Feld mit den Benutzerverzeichnissen innerhalb des Abschnitts platziert wird. Dazu definierst du hier einen Reihenfolgeindex zwischen 1 und 1000. Lässt du den Wert weg, wird 800 verwendet, welches die Standartreihenfolge verwendet.
Die folgende Illustration zeigt ein Beispiel wie der Reihenfolgeindex des Felds die Reihenfolge innerhalb jedes Abschnitts definiert.
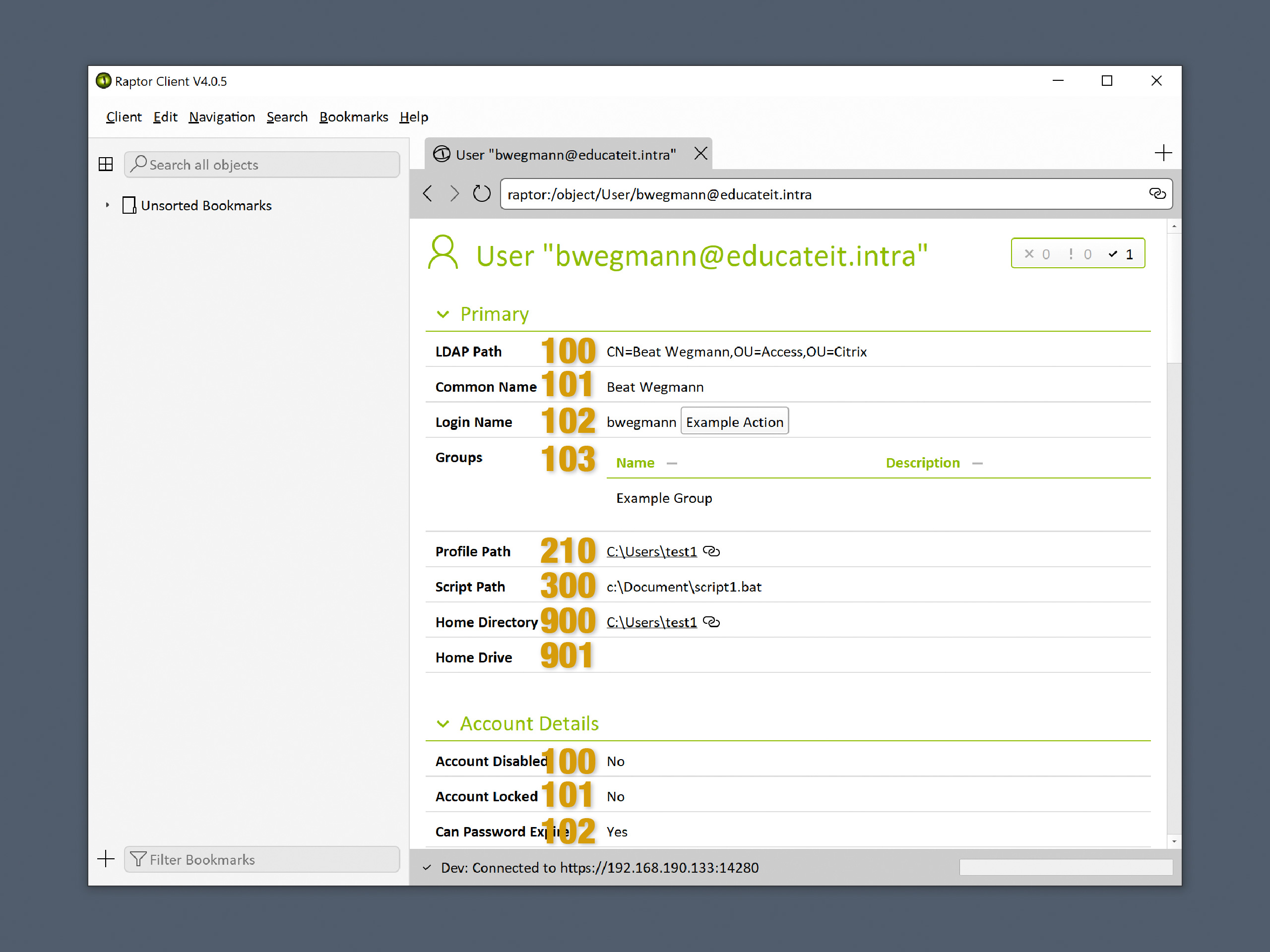
Die Reihenfolgeindexe definieren die Reihenfolge der Felder im Client¶
Das folgende Beispiel setzt den Reihenfolgeindex auf den Wert 120 und verschiebt damit das Feld weiter nach oben:
<Value name="ValueOrderIndex">120</Value>
Die Liste TableColumns und TableActions¶
Mit den optionalen Liste TableColumns und TableActions, kannst du die Tabelle mit den Benutzerverzeichnissen praktisch beliebig anpassen. Lässt du diese Listen weg, wird die Tabelle mit dem default Layout angezeigt.
Alle Details zu diesem Thema findest du im Kapitel Tabellenkonfiguration.
Die folgende Tabelle zeigt dir alle möglichen Spalten welche du in deiner Tabelle verwenden kannst:
Bezeichner |
Typ |
Beschreibung |
|---|---|---|
|
Text |
Der konfigurierte Bezeichner des Eintrags |
|
Text |
Der konfigurierte Name |
|
Text |
Der Verzeichnispfad |
|
Zahl |
Die Grösse des Verzeichnisses |
|
Zahl |
Die Limite für das Verzeichniss |
|
Zahl |
Wie viel der Limite bereits verwendet wird in Prozent |
|
Der Bezeichner für die Spalte mit den Aktionen |
Das folgende Beispiel konfiguriert ein eigenes Layout für die Tabelle:
<List name="TableColumns">
<ListEntry>
<Value name="Identifier">Name</Value>
</ListEntry>
<ListEntry>
<Value name="Identifier">Path</Value>
</ListEntry>
<ListEntry>
<Value name="Identifier">Usage</Value>
</ListEntry>
<ListEntry>
<Value name="Identifier">Size</Value>
<Value name="Title">Total Size</Value>
</ListEntry>
</List>
Der Wert SizeFormat¶
Mit dem optionalen Wert SizeFormat wählst du das Format in welchem die Verzeichnisgrössen angezeigt werden. Dabei hast du die Wahl zwischen zwei verschiedenen Formaten:
Bezeichner |
Format |
|---|---|
|
Der Wert wird als einfache Zahl mit der anzahl der Bytes angezeigt. |
|
Der Wert wird in einem kurzen Format, mit einem passenden Suffix angezeigt. |
Das folgende Beispiel zeigt dir, wie du die Ausgabe als einfache Zahl konfigurierst:
<Value name="SizeFormat">Bytes</Value>
Lässt du diesen Wert weg, wird der Standartwert Formatted verwendet.
Der Wert TextOnError¶
Mit dem optionalen Wert TextOnError` kannst du einen individuellen Text bei Fehlern setzen. Dieser Text wird in der Tabelle für Einträge angezeigt, welche nicht berechnet werden konnten. Dieser Text muss kurz sein, maximal 64 Zeichen und darf keine Sonderzeichen enthalten.
Lässt du diesen Wert weg, wird der Standartwert [error] verwendet.
Die Liste Paths¶
Mit der Liste Paths konfigurierst du die Quellen für alle angezeigten Benutzerverzeichnisse. Mit jedem Eintrag in dieser Liste kannst du einen oder mehrere Verzeichnisse erzeugen, welche der Tabelle hinzugefügt werden.
Du kannst dabei einfach einen bestehenden Wert des Objekts verwenden, optional diesen mit einem Skript modifizieren oder gar den Wert komplett mit einem Skript erzeugen, ohne Eingabewerte aus dem Objekt.
Der Wert Identifier¶
Der optionale Wert Identifier kann ein eindeutiger Bezeichner für eine Quelle sein. Diesen Bezeichner kannst du dann beispielsweise in deinen Skripten verwenden um einzelne Quellen zu unterscheiden.
Lässt du diesen Wert weg, wird ein Bezeichner automatisch generiert.
Der Wert Name¶
Mit dem optionalen Wert Name kannst du einem Verzeichnispfad einen Namen geben, der in der Tabelle angezeigt wird. Dieser Name ist reine Dekoration und hat für das System keine Bedeutung. Lässt du den Namen weg ist dieser leer für die konfigurierte Quelle.
Der Wert InformationBlockName¶
Mit dem Wert InformationBlockName wählst du den Informationsblock aus welchem ein Wert für die Quelle des Pfads ausgewählt wird. Dieser Wert in kombination mit ValueName wählt den Eingabewert für diese Quelle.
Mit dem speziellen Bezeichner None gibst du an, dass ein folgender Skript ohne Eingabewert auskommt.
Der Wert ValueName¶
Mit dem Wert ValueName wählst du den Wert aus dem in InformationBlockName konfigurierten Informationsblock. Dieser Wert in kombination mit InformationBlockName wählt den Eingabewert für diese Quelle.
Mit dem speziellen Bezeichner None gibst du an, dass ein folgender Skript ohne Eingabewert auskommt.
Der Wert Script¶
Der optionale Wert Script definiert einen Skript welcher entweder den Eingabewert konvertiert/verwendet oder ohne Eingabewert einen oder mehrere Pfade erzeugt. Details dazu findest du in Kapitel Betriebsarten der Pfad-Einträge und Das Skript Interface.
Der Wert RemoveNonExistingPaths¶
Mit der Option RemoveNonExistingPaths wählst du, ob nicht existierende Pfade aus der Tabelle entfernt werden sollen. Setzt du diesen Wert auf Yes, wird jeder Pfad überprüft und falls er nicht gefunden wird entfernt.
Lässt du diesen Wert weg, wird der Standartwert No verwendet. In diesem Fall werden alle Pfade behalten, unabhängig davon ob sie tatsächlich vorhanden sind.
Die Liste Limits¶
Mit der Liste Limits konfigurierst du die Limiten für einen Pfad. Alle Einträge in dieser Liste werden in der Reihenfolge getestet, in der du sie definierst. Sobald einer der Einträge auf einen Pfad passt wird dessen konfigurierte Limite verwendet. Danach werden keine weiteren Einträge mehr getestet.
Der Wert Identifier¶
Mit dem optionalen Wert Identifier kannst du einem Eintrag in der Liste einen eindeutigen Bezeichner geben. Dieser Bezeichner wird in der Logdatei verwendet, damit du einen Eintrag eindeutig identifizieren kannst.
Lässt du den Wert weg, wird automatisch ein eindeutiger Bezeichner generiert.
Der Wert PathFilter¶
Der optionale Wert PathFilter definiert einen Regulären Ausdruck welcher auf den den Pfad passen muss. Falls du einen Regulären Ausdruck definierst, muss dieser auf den Pfad passen, ansonsten wird dieser Eintrag übersprungen. Lässt du diesen Wert weg, passt dieser Eintrag auf jeden Pfad.
Der Wert InformationBlockName¶
Mit dem Wert InformationBlockName wählst du den Informationsblock aus welchem ein Wert für die Quelle der Limite ausgewählt wird. Dieser Wert in Kombination mit ValueName wählt den Eingabewert für diese Quelle.
Mit dem speziellen Bezeichner None gibst du an, dass ein folgender Skript ohne Eingabewert auskommt.
Im Kapitel Betriebsarten der Limit-Einträge findest du Details dazu, wie ein Eingabewert interpretiert werden kann.
Der Wert ValueName¶
Mit dem Wert ValueName wählst du den Wert für die Quelle der Limite, aus dem in InformationBlockName konfigurierten Informationsblock. Dieser Wert in Kombination mit InformationBlockName wählt den Eingabewert für diese Quelle.
Mit dem speziellen Bezeichner None gibst du an, dass ein folgender Skript ohne Eingabewert auskommt.
Im Kapitel Betriebsarten der Limit-Einträge findest du Details dazu, wie ein Eingabewert interpretiert werden kann.
Der Wert Script¶
Der optionale Wert Script definiert einen Skript welcher entweder den Eingabewert konvertiert/verwendet oder ohne Eingabewert eine Limite erzeugt. Details dazu findest du in Kapitel Betriebsarten der Limit-Einträge und Das Skript Interface.
Der Wert Factor¶
Mit dem optionalen Wert Factor konfigurierst du einen Faktor um den Eingabewert in eine Limite zu konvertieren. Definierst du einen Faktor, wird der Eingabewert, den du mit InformationBlockName und ValueName konfiguriert hast mit dem Faktor multipliziert und als Limite verwendet.
Du kannst entweder ein Skript oder ein Faktor verwenden, aber nicht beides.
Der Wert JobProcessingTimeout¶
Mit dem optionalen Wert JobProcessingTimeout änderst du, wie lange ein Job dauern darf. Dieser Wert wird in Sekunden angegeben.
Wir empfehlen diesen Wert wegzulassen und den Standartwert zu verwenden.
Der Wert JobSizeCalculationTimeout¶
Mit dem optionalen Wert JobSizeCalculationTimeout änderst du, wie lange die Berechnung von Verzeichnisgrössen dauern darf. Dieser Wert wird in Sekunden angegeben.
Wir empfehlen diesen Wert wegzulassen und den Standartwert zu verwenden.
Die Gruppe DirectoryScannerService¶
Mit der Gruppe DirectoryScannerService konfigurierst du alle Angaben für die Verbindung mit dem Directory Scanner Service. Die meisten Werte in dieser Gruppe sind optional, lediglich Key und Secret müssen zwingend angegeben werden.
Der Wert Host¶
Mit dem optionalen Wert Host setzt du den Hostnamen oder die IP Adresse des Servers auf dem der Directory Scanner Service läuft. Lässt du den Wert weg, wird localhost verwendet.
Der Wert Port¶
Mit dem optionalen Wert Port, ändert du den Port welcher für die Verbindung zum Directory Scanner Service verwendet wird. Lässt du diesen Wert weg, wird der Standartwert 17661 verwendet.
Der Wert SslProfile¶
Mit SslProfile bestimmst du die SSL-Konfiguration für deine Verbindung. Stelle sicher, dass der Name, den du hier einfügst, in der Liste profiles im SSL Konfigurationsmodul vorhanden ist. In Kapitel Eigene SSL Zertifikate verwenden erfährst du mehr darüber, wie du das SSL-Profil richtig einrichtest.
Du hast auch die Möglichkeit, diesen Wert auf legacy zu setzen. Das ist besonders hilfreich, wenn du eine Migration durchführen oder ältere Installationen unterstützen möchtest. In diesem Fall verwendet das System die integrierten Zertifikate, die mit älteren Versionen des Directory Scanner Services kompatibel sind.
Warnung
Wir empfehlen allerdings ausdrücklich, immer eigene Zertifikate und Schlüssel zu verwenden. Diese sollten den korrekten Servernamen enthalten und von einer internen Zertifizierungsstelle deines Unternehmens ausgestellt werden. Mit dieser Methode stellst du sicher, dass deine Verbindung sicher und authentifiziert ist.
1<Module name="UserDirectory">
2 ...
3 <Group name="DirectoryScannerService">
4 <Value name="SslProfile">legacy</Value>
5 <Value name="Key">[key]</Value>
6 <Value name="Secret">[secret]</Value>
7 </Group>
8</Module>
Der Wert Key¶
Mit dem Wert Key setzt du den Schlüssel für die Verbindung zu dem Directory Scanner Service. Mehr dazu findest du im Kapitel Das Secret System.
Der Wert Secret¶
Mit dem Wert Secret setzt du das Geheimnis zum Schlüssel für die Verbindung zum Directory Scanner Service. Mehr dazu findest du im Kapitel Das Secret System.
Der Wert ReconnectDelay¶
Mit dem optionalen Wert ReconnectDelay änderst du wie viele Sekunden der Client wartet, nachdem eine Verbindung abbricht. Lässt du diesen Wert weg, wird den Standartwert von 10 Sekunden verwendet.
Wir empfehlen diesen Wert wegzulassen und den Standartwert zu verwenden.
Der Wert StartupTimeout¶
Mit dem optionalen Wert StartupTimeout änderst du wie lange ein Verbindungsaufbau dauern darf. Dieser Wert wird in Sekunden angegeben.
Wir empfehlen diesen Wert wegzulassen und den Standartwert zu verwenden.
Der Wert ShutdownTimeout¶
Mit dem optionalen Wert ShutdownTimeout änderst du wie lange ein Verbindungsabbau dauern darf. Dieser Wert wird in Sekunden angegeben.
Wir empfehlen diesen Wert wegzulassen und den Standartwert zu verwenden.
Der Wert CallTimeout¶
Mit dem optionalen Wert CallTimeout änderst du wie lange eine Abfrage dauern darf. Dieser Wert wird in Sekunden angegeben.
Wir empfehlen diesen Wert wegzulassen und den Standartwert zu verwenden.
Betriebsarten der Pfad-Einträge¶
Für jeden Eintrag in der Paths Liste gibt es verschiedene Betriebsarten:
Ein Wert des Objekts wird direkt als Pfad verwendet.
Ein Wert des Objekts wird mit einem Skript konvertiert.
Ohne Basis wird ein Skript verwendet um alle Pfade zu generieren.
Das folgende Beispiel verwendet den Wert profile aus dem Informationsblock ActiveDirectoryOR als Pfad für das Benutzerprofil. Dieser Wert wird ohne veränderung übernommen. Der Wert profile muss ein Texttyp sein und einen gültigen Absoluten Pfad zu dem Benutzerprofil enthalten.
Mit dem Wert ValueName wird zudem einen eigenen Namen für diesen Pfad definiert, der in der Tabelle angezeigt wird.
<ListEntry>
<Value name="Identifier">PathFromValue</Value>
<Value name="InformationBlockName">ActiveDirectoryOR</Value>
<Value name="ValueName">profile</Value>
</ListEntry>
Das nächste Beispiel verwendet den Wert commonName aus dem Informationsblock ActiveDirectoryOR als Eingabe für einen Skript. Dieser Skript verwendet dann den Wert um daraus einen Pfad zu erzeugen.
<ListEntry>
<Value name="Identifier">PathBasedOnValue</Value>
<Value name="Name">Custom Name</Value>
<Value name="InformationBlockName">ActiveDirectoryOR</Value>
<Value name="ValueName">commonName</Value>
<Value name="Script"><![CDATA[
"//fileserver01/shares/" + value;
]]></Value>
<Value name="RemoveNonExistingPaths">Yes</Value>
</ListEntry>
Das letzte Beispiel verwendet einen Skript ohne einen Eingabewert. Der Skript erzeugt eine Liste mit möglichen Profilpfaden. Dazu verwendet er den Namen des Objekts, der immer verfügbar ist. Jeder der generierten Pfade wird geprüft, ob dieser tatsächlich existiert. Angezeigt werden nur die existierenden Pfade.
<ListEntry>
<Value name="Identifier">ExistingCheck</Value>
<Value name="InformationBlockName">None</Value>
<Value name="ValueName">None</Value>
<Value name="Script"><![CDATA[
var paths = [
"//fileserver01/shares/" + objectName,
"//fileserver02/shares/" + objectName,
"//fileserver03/shares/" + objectName,
"//fileserver04/shares/" + objectName,
"//fileserver05/shares/" + objectName];
paths;
]]></Value>
<Value name="RemoveNonExistingPaths">Yes</Value>
</ListEntry>
Betriebsarten der Limit-Einträge¶
Für jeden Eintrag in der Limits Liste gibt es drei verschiedene Betriebsarten:
Ein Wert des Objekts wird als Limit verwendet. Optional wird dieser mit einem Faktor multipliziert.
Ein Wert des Objekts wird mit einem Skript in eine Limite umgewandelt. Optional verwendet der Skript zusätzlich den Namen und Kontext des Objects, sowie der Pfad selbst.
Ein Skript erzeugt die Limite ohne Eingabewerte, oder optional mit dem Pfad und/oder mit dem Namen und Kontext des Objekts.
<ListEntry>
<Value name="Identifier">SimpleValue</Value>
<Value name="InformationBlockName">ActiveDirectoryOR</Value>
<Value name="ValueName">profileLimit</Value>
</ListEntry>
<ListEntry>
<Value name="Identifier">ValueFromObject</Value>
<Value name="PathFilter">(?i)/example/</Value>
<Value name="InformationBlockName">ActiveDirectoryOR</Value>
<Value name="ValueName">profileLimitMb</Value>
<Value name="Factor">1000000</Value>
</ListEntry>
<ListEntry>
<Value name="Identifier">LimitBasedOnPathLength</Value>
<Value name="InformationBlockName">None</Value>
<Value name="ValueName">None</Value>
<Value name="Script"><![CDATA[
path.length * 1000000;
]]></Value>
</ListEntry>
<ListEntry>
<Value name="Identifier">ParsedLimit</Value>
<Value name="InformationBlockName">ActiveDirectoryOR</Value>
<Value name="ValueName">profileLimit</Value>
<Value name="Script"><![CDATA[
var result = 0;
var match = /(\d+)(m|g)/.exec(value);
if (match) {
var amount = parseInt(match[1]);
var suffix = match[2];
if (suffix == "m") {
amount *= 1000000;
} else if (suffix == "g") {
amount *= 1000000000;
}
result = amount;
}
result;
]]></Value>
</ListEntry>
Das Format der Eingabewerte¶
Falls du Eingabewerte ohne Skript verwendest, werden bereits einige Formatierungen des Wertes interpretiert. Eine Ganzzahl, ohne Suffix wird dabei immer als Bytes interpretiert. Ein solcher Wert kannst du mit dem Faktor grössere Angaben umwandeln.
Textwerte können entweder einfache Ganzzahlen sein, oder einer der folgenden Suffixe enthalten:
Suffix |
Factor |
|---|---|
|
1 |
|
1000 |
|
10002 |
|
10003 |
|
10004 |
|
10005 |
|
10006 |
|
10007 |
|
10008 |
|
1024 |
|
10242 |
|
10243 |
|
10244 |
|
10245 |
|
10246 |
|
10247 |
|
10248 |
Die Gross-/Kleinschreibung der Suffixe wird nicht beachtet. Es kann auch ein Leerzeichen zwischen der Zahl und dem Suffix stehen. Zahlen mit Suffixen können auch Nachkommastellen enthalten, sie werden jedoch immer auf eine ganze Zahl von Bytes gerundet.
Das Skript Interface¶
Ein Skript muss gültiger JavaScript sein, schnell ausgeführt werden und in keinem Fall die Ausführung blockieren. Es existieren eine Reihe von globalen Variablen welche jeder Skript verwenden kann. Der Skript kann nur diese Variablen als Eingabewerte verwenden, sonst hat er keinen Zugriff auf die Umgebung. Diese Variablen werden in der folgenden Tabellen erklärt.
Interface für Pfade¶
Variable |
Beschreibung |
|---|---|
|
Diese Variable enthält den Wert des Objekts welcher Konfiguriert wurde. Handelt es sich dabei um komplexe Werte, wie beispielsweise Tabellen, entspricht das Format dem eines Objektexports aus dem Client. |
|
Der Name des aktuellen Objekts. |
|
Der Kontext des aktuellen Objekts. |
|
Der Typ des aktuellen Objekts. |
Interface für Limiten¶
Variable |
Beschreibung |
|---|---|
|
Diese Variable enthält den Wert des Objekts welcher Konfiguriert wurde. Handelt es sich dabei um komplexe Werte, wie beispielsweise Tabellen, entspricht das Format dem eines Objektexports aus dem Client. |
|
Der Pfad der für diese Limite verarbeitet wird. Es handelt sich dabei um genau den Pfad, der durch den |
|
Der Name des aktuellen Objekts. |
|
Der Kontext des aktuellen Objekts. |
|
Der Typ des aktuellen Objekts. |
JavaScript Implementierung¶
Die Skript-Engine unterstützt eine moderne und komplette implementation von JavaScript wie sie in ECMA-262 spezifiziert ist.
Rückgabewert für Pfade¶
Als Rückgabewert muss der Skript entweder ein Text (String) oder ein Array von Texten zurückliefern. Dazu schreibst du den Wert einfach als letzten Wert in den Skript ohne ein return Statement. Schau dir dazu nochmals die Beispiele weiter oben an.
Rückgabewert für Limiten¶
Bei Limiten muss der Skript einen Integerwert zurückliefern. Dieser Wert definiert die Limite in Bytes. Dazu schreibst du den Wert einfach als letzten Wert in den Skript ohne ein return Statement. Schau dir dazu nochmals die Beispiele weiter oben an.
Es gibt zwei Spezialwerte welche du zurückliefern kannst:
Gib
0zurück, falls der Pfad kein Limit hat.Gib
-1zurück um diesen Eintrag zu überspringen und weitere Einträge in der Konfiguration zu prüfen.